一、组件化思考
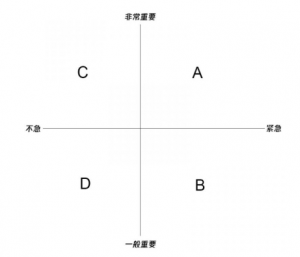
组件的存在的终极意义是为了复用,一个组件只要具备了被复用的条件,并且开始被复用,那么它的价值才开始产生。组件复用的次数越高、被传播的越广,其价值就越大。而要实现组件的价值最大化,需要考虑以下几点:
- 1. 我要写一个什么组件?组件提供什么样的能力?
- 2. 组件的适用范围是什么?某个具体业务系统内还是整个团队、公司或者社区?
- 3. 组件的生产过程是否规范、健壮和值得信赖?
- 4. 组件如何被开发者发现和认识?
二、组件化规范
一个优秀的组件除了拥有解决问题的价值,还应该具备以下三个特点:
- 1. 生产和交付的规范性
- 2. 优秀的质量和可靠性
- 3. 较高的可用性
只有三者都能满足才可以称其为优秀组件,否则会给使用者带来各种各样的困惑:经常出Bug、坑很多、不稳定、文档太简单、不敢用等等。
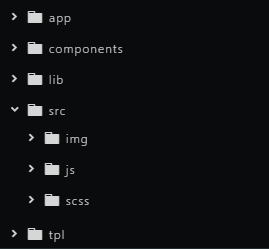
2.1 目录结构
事实上,并没有一个官方的目录结构规范,但从耳熟能详的知名项目中进行统计和分析,可以得出一个社区优秀开发者达成非官方共识的一个目录结构清单:
├─ test // 测试相关
├─ scripts // 自定义的脚本
├─ docs // 文档,通常文档较多,有多个md文档
├─ examples // 可以运行的示例代码
├─ packages // 要发布的npm包,一般用在一个仓库要发多个npm包的场景
├─ dist|build // 代码分发的目录
├─ src|lib // 源码目录
├─ bin // 命令行脚本入口文件
├─ website|site // 官方网站相关代码,譬如antd、react
├─ benchmarks // 性能测试相关
├─ types|typings// typescript的类型文件
├─ Readme.md // 仓库介绍或者组件文档
└─ index.js // 入口文件以上目录清单是一个比较完整的清单,大多数组件只需要根据自己的需求选择性地使用一部分即可。一份几乎适用于所有组件的最小目录结构清单如下:
├─ test // 测试相关
├─ src|lib // 源码目录
├─ Readme.md // 仓库介绍或者组件文档
└─ index.js // 入口文件2.2 配置文件
主要指的是各种工程化工具所依赖的本地化的配置文件,以及在Github上开源所需要声明的一些文件。一份比较全的配置文件清单如下:
├─ .circleci // 目录。circleci持续集成相关文件
├─ .github // 目录。github扩展配置文件存放目录
│ ├─ CONTRIBUTING.md
│ └─ ...
├─ .babelrc.js // babel 编译配置
├─ .editorconfig // 跨编辑器的代码风格统一
├─ .eslintignore // 忽略eslint检测的文件清单
├─ .eslintrc.js // eslint配置
├─ .gitignore // git忽略清单
├─ .npmignore // npm忽略清单
├─ .travis.yml // travis持续集成配置文件
├─ .npmrc // npm配置文件
├─ .prettierrc.json // prettier代码美化插件的配置
├─ .gitpod.yml // gitpod云端IDE的配置文件
├─ .codecov.yml // codecov测试覆盖率配置文件
├─ LICENSE // 开源协议声明
├─ CODE_OF_CONDUCT.md // 贡献者行为准则
└─ ... // 其他更多配置
以上配置可以根据组件的实际情况,适用范围来进行删减。一份在各种场景都比较通用的清单如下:
├─ .babelrc.js // babel 编译配置
├─ .editorconfig // 跨编辑器的代码风格统一
├─ .eslintignore // 忽略eslint检测的文件清单
├─ .eslintrc.js // eslint配置
├─ .gitignore // git忽略清单
├─ .npmignore // npm忽略清单
├─ LICENSE // 开源协议声明
└─ ... // 其他更多配置
上述清单移除了只有在Github上才用得到的配置,只关注仓库管理、发包管理、静态检查和编译这些基础性的配置,适用于团队内部、企业私有环境的组件开发。如果要在Github上维护,则还需要从大清单中继续挑选更多的基础配置,以便可以使用Github的众多强大的功能。
2.3 package.json
package.json文件,这是发包时唯一不可或缺的文件。一个最精简的package.json文件是执行npm init生成的这个版本:
{
"name": "npm-speci-test", // 组件名
"version": "1.0.0", // 组件当前版本
"description": "", // 组件的一句话描述
"main": "index.js", // 组件的入口文件
"scripts": { // 工程化脚本,使用npm run xx来执行
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "", // 组件的作者
"license": "ISC" // 组件的协议
}作为一个规范的组件,我们还需要考虑: 1. 我的代码托管在什么位置了 2. 别人可以在仓库里通过哪些关键词找到组件 3. 组件的运行依赖有哪些 4. 组件的开发依赖有哪些 5. 如果是命令行工具,入口文件是哪个 6. 组件支持哪些node版本、操作系统等
一份比较通用的package.json文件内容如下:
{
"name": "@scope/xxxx",
"version": "0.1.0",
"description": "description:xxx",
"keywords": "keyword1, keyword2,...",
"main": "./dist/index.js",
"bin": {},
"scripts": {
"lint": "eslint --ext ./src/",
"test": "npm run lint & istanbul cover _mocha -- test/ --no-timeouts",
"build": "npm run lint & npm run test & gulp"
},
"repository": {
"type": "git",
"url": "http://github.com/xxx.git"
},
"author": {
"name": "someone",
"email": "someone@gmail.com",
"url": "http://someone.com"
},
"license": "MIT",
"dependencies": {},
"devDependencies": {
"eslint": "^5.2.0",
"eslint-plugin-babel": "^5.1.0",
"gulp": "^3.9.1",
"gulp-rimraf": "^0.2.0",
"istanbul": "^0.4.5",
"mocha": "^5.2.0"
},
"engines": {
"node": ">=8.0"
}
}name属性要考虑的是组件是否为public还是private,如果是public要先确认该名称是否已经被占用,如果没有占用为了稳妥起见,可以先发一个空白的版本;如果是private的,则需要加上@scope前缀,同样也需要确认名称是否已被占用。version属性必须要符合semver规范,简单理解就是:- 第一个版本一般建议用0.1.0
- 如果当前版本有破坏性变更,无法向前兼容,则考虑升第一位
- 如果有新特性、新接口,但可以向前兼容,则考虑升第二位
- 如果只是bug修复,文档修改等不影响兼容性的变更,则考虑升第三位
keywords会影响在仓库中进行检索的结果main入口文件的位置最好可以固定下来,如果组件需要构建,建议统一设置为./dist/index.js, 如果不需要构建,可以指定为根目录下的index.jsscriptsscripts通常会包含两部分:通用脚本和自定义脚本。无论是个人还是团队,都应该为通用脚本建立规范,避免过于随意的命名scripts;自定义脚本则可以灵活定制,比如:- 通用scripts:start、lint、test、build
- 自定义scripts:copy、clean、doc等
repository属性无论在私有环境还是公共环境,都应该加上,以便通过组件可以定位到源码仓库author如果是一个人负责的组件,用author,多个人就用contributors
2.4 流程
保障并行多个版本,并且每一个发布的版本可回溯即可,统一采用分支开发,用master作为线上分支和预发分支,开发分支要发版需要预先合并到master上,然后再master上review和单测后直接发布,并打tag标签
2.5 README.md && changelog
Readme文件是对项目的基本介绍,直接关系到组件能不能更容易被他人使用。组件的readme文件一般包括以下部分内容:
- 组件基本介绍
- 组件开发环境
- 组件使用说明(重要)
- 组件API参考(重要)
- 注意事项
changelog一般是记录每个版本更新的差异,可以单独用一个文件记录,也可以在readme底部记录,功能或者api的变更一定要有相应的log
2.6 Demo
对一个组件而言,demo的重要性不言而喻,demo更侧重于具体场景中的用法,一般在项目根目录的example文件夹存放项目的demo,对于较小的组件,也可以和readme合并
2.7 单元测试
单元测试需要一定的开发成本,对于业务类的组件,可以不写单元测试。
但是对于功能组件、UI组件就很有必要写单元测试,以保障组件的可用性和质量。